The trouble with TOTP
RFC6238 is a time-based protocol based off RFC4226. The basic protocol (both client and server) is:
HOTP(k, c) =
DT( HMACSHA1k(c) ) mod 1000000
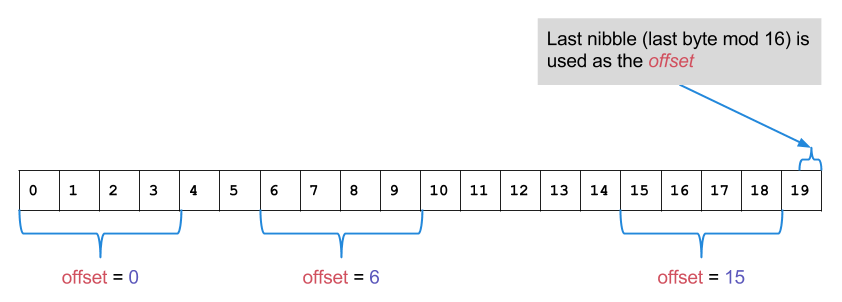
DT(X) =
offset := X[19] mod 16
return X[{ offset .. offset+3 }]
In this protocol, k is a secret key that is shared with the client (eg. smartphone app
or keyfob) and the server. In RFC4226 c is a counter which must increase on each use.
In RFC6238 c is redefined as a timestamp, which is the number of seconds since the
start of Jan 1, 1970 UTC cast as a 64-bit integer and divided by 30.
The dynamic truncate function is rather arbitrary - possibly it was intended as a nothing-up-my-sleeves truncate, but the design decisions that led to it aren’t documented (and the RFC authors didn’t respond to my emails regarding it). If the HMAC is secure then there shouldn’t be any problem with it apart from it’s extremely small resulting hash length. It doesn’t re-use the last byte (offset=15 would select {15, 16, 17, 18}) and in theory all of the bytes in HMAC-SHA1 should act like a truncated random oracle.
The modulo operation introduces a tiny amount of bias - for every 231 samples numbers above 483647 would be selected 2147 times, while smaller numbers would be selected 2148 times.
What’s most concerning about the modulo operation is that there’s only 1 million possible OTP values! Now I’m sure you’re thinking that somebody having a 1 in a million chance of breaking into your account if they get your password is pretty good - but that’s not the way this game works.
If we take a look at page 7 of rfc6238 you’ll see the authors talking about syncing, and what seems like a recommendation that you accept two time-steps backwards in order to resync with clients who’s half a cent clock chip is moving slow - along with all sorts of warnings about the bad things that will happen if you make this number too big. The thing is that even if we only account 2 extra timesteps (1 back, 1 forward), that divides the number space by 3 - now it’s a 1 in 333,333 chance of guessing your OTP.
But hold on - I’m not done here! It turns out that locking out an account after a single bad guess isn’t user-friendly. So instead they recommend a backoff timer of 5 seconds times the number of bad attempts. But trying more than once at all is increasing the chances of an attacker getting lucky guess.
Now for the insane part - you’re not the only person using this protocol!
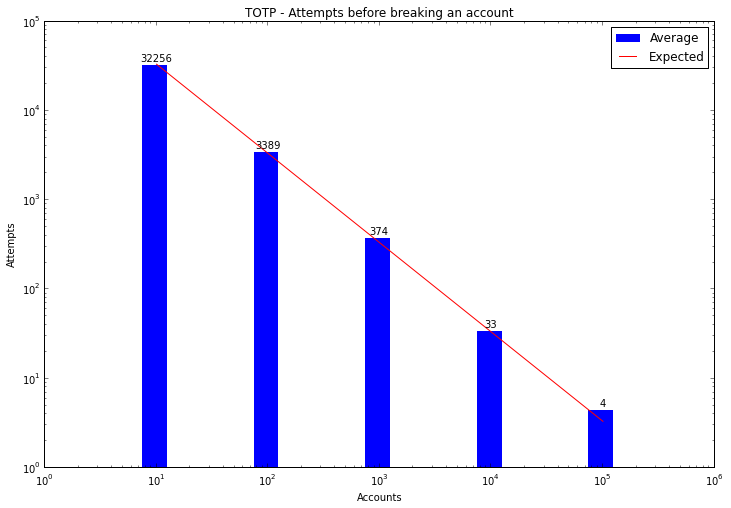
If an attacker (such as a spammer) purchased a large list of compromised first factors, they could simply run a bot trying as often as possible against all accounts they have. Spammer’s aren’t fussy - any account will do for a spam run. So if they have 10,000 accounts, they’d only need an average of 33 tries (against all accounts) before they pop one. The laws of averages don’t care whether the accounts are all on the same server - indeed for their purposes the more systems it’s spread over the better.
Based on the backoff timer recommendations in the rfc, 100 attempts would take 7 hours, 1000 attempts would take 29 days, and 10,000 attempts would take 8 years. In any case, trying to wear out the patience of spam bots is a bad plan.
Now I hear you thinking all those things about locking out IP addresses, requiring users’ D.O.B and mother’s maiden name after a bad guess and all that other stuff. But that’s not the point - we want two-factor protocols so that you can worry less about that stuff.
The best fix would be to do away with Dynamic Truncate, and simply base-32 encode the digest (eg. 32 unambiguous numbers and case insensitive letters). Now truncate that output to a minimum of 8 characters (40 bits) - if you can do 16 characters that would be better, but you’ll want to make the time-range longer.
Keep in mind that you’re asking people to read the OTP, not remember it.
This was presented as part of my Ruxcon 2013 talk Under the hood of your password generator. I also presented on S/Key and Random password generators